What seems like a looong time ago I came up with an idea for “bootstrapping” the Non API Web (NAW), particularly around extracting un-structured content from (museum) collections pages.
The idea of scraping pages when there’s a lack of data access API isn’t new: Dapper launched a couple of years ago with a model for mapping and extracting from ‘ordinary’ html into a more programmatically useful format like RSS, JSON or XML. Before that there have been numerous projects that did the same (PiggyBank, Solvent, etc); Dapper is about the friendliest web2y interface so far, but it still fails IMHO in a number of ways.
Of course, there’s always the alternative approach, which Frankie Roberto outlined in his paper at Museums and the Web this year: don’t worry about the technology; instead approach the institution for data via an FOI request…
The original prototype I developed was based around a bookmarklet: the idea was that a user would navigate to an object page (although any templated “collection” or “catalogue” page is essentially the treated the same). If they wanted to “collect” the object on that page they’d click the bookmarklet, a script would look for data “shapes” against a pre-defined store, and then extract the data. Here’s some screen grabs of the process (click for bigger)
 | An object page on the Science Museum website |
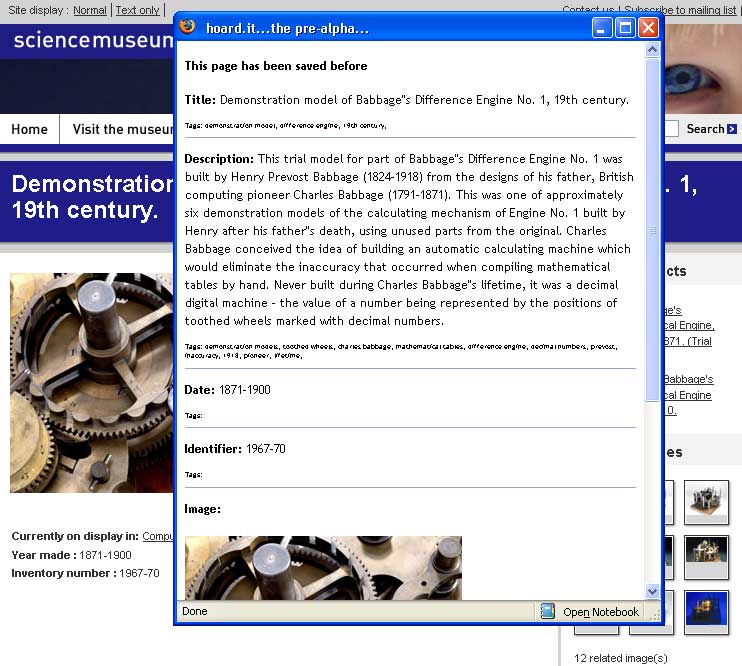 | User clicks on the bookmarklet and a popup tells them that this page has been “collected” before. Data is separated by the template and “structured” |
 | Here, the object hasn’t been collected but the tech spots that the template is the same, so knows how to deal with the “data shape” |
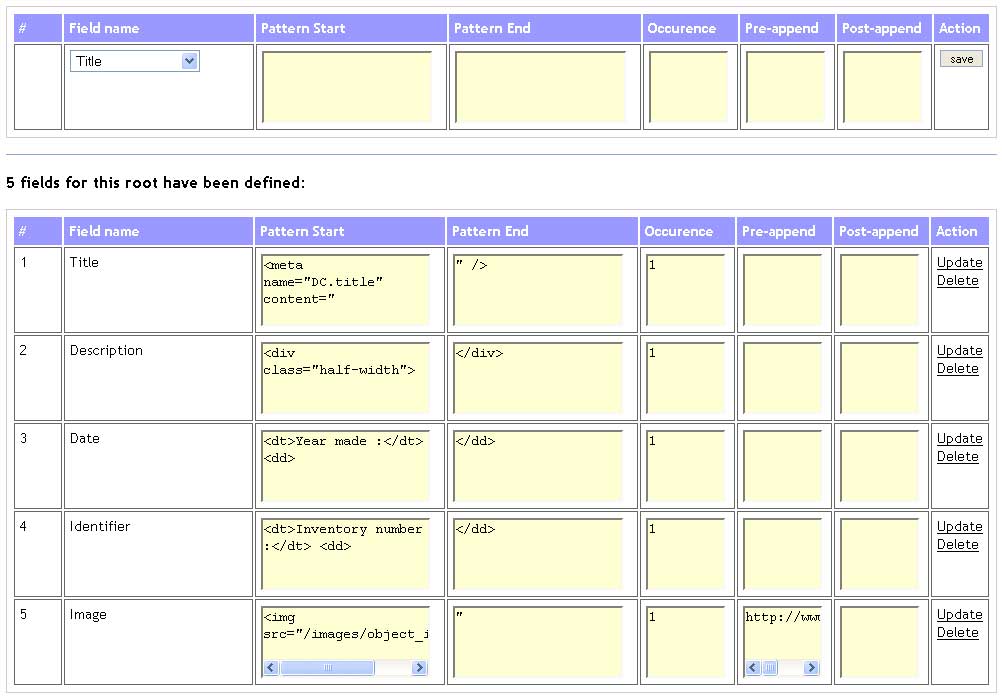 | The hoard.it interface, showing how the fields are defined |
I got talking to Dan Zambonini a while ago and showed him this first-pass prototype and he got excited about the potential straight away. Since then we’ve met a couple of times and exchanged ideas about what to do with the system, which we code-named “hoard.it”.
One of the ideas we pushed about early on was the concept of building web spidering into the system: instead of primarily having end-users as the “data triggers”, it should – we reasoned – be reasonably straightforward to define templates and then send a spider off to do the scraping instead.
The hoard.it spider
Dan has taken that idea and run with it. He built a spider in PHP, gave it a set of rules for templates and link-navigation and set it going. A couple of days ago he sent me a link to the data he’s collected – at time of writing, over 44,000 museum objects from 7 museums.
Dan has put together a REST-like querying method for getting at this data. Queries are passed in via URL and constructed in the form attribute/value – the query can be as long as you like, allowing fine-grained data access.
Data is returned as XML – there isn’t a schema right now, but that can follow in further prototypes. Dan has done quite a lot of munging to normalise dates and locations and then squeezed results into a simplified Dublin Core format.
Here’s an example query (click to see results – opens new window):
So this means “show me everything where location.made=Japan'”
Getting more fine-grained:
Yes, you guessed it – this is “things where location.made=Japan and dc.subject=weapons or entertainment”
Dan has done some lovely first-pass displays of ways in which this data could be used:
- A randomly selected gallery of 100 objects
- “100 years of British Culture”
- my favourite: a world map showing object locations
Also, any query can be appended with “/format/html” to show a simple html rendering of the request:
What does this all mean?
The exposing of museum data in “machine-useful” form is a topic about which you’ll have noticed I’m pretty passionate. It’s a hard call, though (and one I’m working on with a number of other museum enthusiasts) – to get museums to understand the value of exposing data in this way.
The hoard.it method is a lovely workaround for those who don’t have, can’t afford or don’t understand why machine-accessible object data is important. On the one hand, it’s a hack – screenscraping is by definition a “dirty” method for getting at data. We’d all much prefer it if there was a better way – preferably, that all museums everywhere did this anyway. But the reality is very, very different. Most museums are still in the land of the NAW. I should also add that some (including the initial 7 museums spidered for the purposes of this prototype) have some API’s that they haven’t exposed. Hoard.it can help those who have already done the work of digitising but haven’t exposed the data in a machine-readable format.
Now that we’ve got this kind of data returned, we can of course parse it and deliver back…pretty much anything, from mobile-formatted results to ecards to kiosk to…well, use your imagination…
What next?
I’m running another mashed museum day the day before the annual Museums Computer Group conference in Leicester, and this data will be made available to anyone who wants to use it to build applications, visualisations or whatever around museum objects. Dan has got a bunch of ideas about how to extend the application, as have I – but I guess the main thing is that now it’s exposed, you can get into it and start playing!
How can I find out more?
We’re just in the process of putting together a simple series of wiki pages with some FAQ’s. Please use that, or the comments on this post to get in touch. Look forward to hearing from you!
You guys rock.
I think that’s the nicest comment I’ve ever had on my blog 🙂 – thanks!!
Nice one, Dan and Mike!
Some random thoughts while I wait for a compile to finish…
Which museums? I know one was the Museum of London, but what are the others, and how were they chosen?
Randomly, I’m working on a personal project that might require finding resources (images, authority records) about particular people, events and groups from many different museums and other websites and working out how to collect cohesive ‘pages’ about them so they can be further annotated and written about. I’m still at the stage of thinking about whether to display these resources within the page or link to them, so I’ll probably have a play with the scraped data soon.
One issue I’ll probably run into is that repositories or other defined single points of access might be more stable data sources (less liable to URIs changing than exhibition microsites or catalogue pages etc) but there aren’t many around, so we’re stuck with these ad hoc methods. I’ll let you know how it works for me if I get a chance to play with it before the mashed museum day.
One of my questions about this kind of stuff generally is about the stability and permanence of the data. And what about updates (additions or corrections) made to the original online record back on the museum site? Another argument for APIs for museum collections, I guess.
It would be lovely if these kinds of demonstrations led to a better understanding of the possibilities of re-usable digital data. Have you had much feedback from non-technical people – the curators, educators, researchers, general visitors, etc?
Mia, thanks for the comment.
You can see which museums we chose (and the number of objects currently spidered from each) at http://feeds.boxuk.com/museums/
As for ‘method for choosing them’, well, that was more a case of just looking through some of the major museum sites, and seeing if their collections data was available online in a suitable format (a common template, not hidden behind session-dependencies or form POSTs).
Re:updates; this is just a prototype at the moment, but there’s no reason we couldn’t re-spider pages (in the same way Google does) checking for changes to the data, and updating as necessary. Though I don’t have plans to do that quite yet… But yes, this is definitely a ‘workaround’ for APIs, rather than a better alternative.
Haven’t had much feedback from non-techies yet, but then we’ve only just announced it, so we’ll see!
Well done guys, only looked at Mike’s description about, and the pre-alpha months ago, so this is an initial response (from a techie again, sorry!)
As you know, I did some playing with the idea of a microformat or some sort of POSH for museum objects, and using a bookmarklet to let users build and annotate their own collection of stuff, sort of like a domain-specific but richer del.icio.us (like hoard.it, an API is a key aim for accessing the data. Difference is I didn’t get around to making it…). The drawback of that approach, of course, is that the web techs need to put their data out in that format. On the other hand, it’s possibly more flexible than a (basic) screen scraping approach, in that the structure for your POSH should be (a) explicitly documented somewhere and (b) more like a schema than a template (which might say “look for the div just after the header, take the H1 and paras in it and do….” – microformats give you the confidence to make more sophisticated transformations).
What you’ve done get’s over a huge bump by avoiding the need for museum web techs to actually do anything to their HTML (a lot of the time) – instead the hard work is done by whoever makes the templates. So this is a great kick-start. I wonder, though, whether once hoard.it has shown the community the benefits of client-side gathering by bookmarklets, or server-side spidering, the next step might be to try to settle on and evangelise some POSH conventions. My experiments were aimed at requiring a minumum – one could just indicate the existence of a better source of data on an object (perhaps the metadata in the head of a page, or some XML source) and the gatherer could grab that instead of the embedded POSH, and the plan was for it then to be able to accept either the POSH format OR something like CDWALite, SPECTRUM XML etc.
So, do you think there’s scope for POSH to push this further?
Hey Jeremy
I’m not the one who built the templates or “shape” definitions, so DZ might be better placed to answer…but certainly in my experience (and I think in Dan’s build, too), the more structured the data, the better. On sites like http://www.ingenious.org.uk for example, we (NMSI) built in metadata into the HEAD and this makes it a breeze for hoard.it to parse out content as the original site intended, rather than as we (hoard.it) are interpreting it. I also heard him swearing at the British Museum markup which was hugely inconsistent from page to page… 🙂
Certainly in my original idea, the system was envisaged to work with a cascading approach. So, for instance, it would look in the first instance for evidence of full structured data associated with the page – say RDF, API or RSS, use that if found; if not, look for microformatty stuff then POSH, finally defaulting to “unstructured” HTML if none of the above was found.
I think in this instance, because of the rapid dev, the templates don’t do any of this automatically but it is determined when DZ writes the template for each site. So in the Ingenious examples, Dan looked at the source and saw that structure, so used it to drag out the data. In other sites, it didn’t exist so he just used the lowest common denominator – HTML markup.
We are now thinking about ways in which you could relate the structured content and the markup. That’s one of our next stages, and would be great to talk to you about your aspirations, too…
Cheers
Mike
Hi Mike. That sounds like quite an expansion of the vision as I originally understood it, and a good approach, if ambitious! I had thought it was always about writing templates on the HTML (which users could do, and obviously still can), as opposed to the system looking for a hierarchy of data “sources” and using the best of them. Perhaps that relates to the spider, though.
The advantage with what you’ve started is that adapting to different data sources is under the control of a template developer i.e. Dan. Of course its strength is a work-around for reality, with the corresponding disadvantage that it requires, say, Dan to build templates for each variation, of which there’ll be many unless one can get agreement on some conventions. I’m just suggesting that your tool makes more apparent the advantage of institutions using some sort of (say) POSH convention, so that they don’t need to get you to create a new template for you to spider their stuff.
I ain’t got any aspirations for Gathery any more, really, but I am keeping a vague eye on microformats for generic objects still, and still wondering whether a very simple bit of POSH based on DC or CDWALite could be worth the candle. The microformat community (parts of it) pooh-poohed the idea of a DC-based uF, though as a very generic set of concepts it seemed to me pretty ideal. But hey, a bit of POSH doesn’t need them, and some GRDDL could get us a long way too.
Yeah, agreed that the onus should be on the site owner (if they wanted..) – I’m looking at an even lighter idea than GRDDL. Basically the concept would be GRDDL-like in that it would allow site developers to be the ones who defined the relationships between markup and data. But it’d be lighter in that I reckon for most people (me included, except for basic stuff..), even XSLT is too heavy.
Watch this space 🙂
Mike
Yep, writing an XSLT transform for GRDDL isn’t necessarily that easy but the point is you don’t have to do it if someone else has done it, which is why Plain Old Semantic Html (i.e. POSH, Mia’s pointed out that I never explained that one) to an agreed form doesn’t need you to write your own transform. There may never be (or need to be) an official microformat for museum objects, but we could agree on a set of conventions and write one or a number of GRDDL tranformations for people to choose from.
Jeremy
Regarding screen scraping, you might find this work “Sifter” interesting:
http://www.vimeo.com/808235
Regarding data integration, see “Potluck”:
http://www.vimeo.com/808214
which has been blogged about by Jon Udell:
http://blog.jonudell.net/2007/12/06/simile-semantic-web-mashups-for-the-rest-of-us/
And regarding creating mashups, see “Exhibit”:
http://simile.mit.edu/exhibit/
Some of these projects dated back quite a few years.
Hey David, cheers for those links. Sifter is pretty impressive – it’d be very interesting to find out more about how it does the analysis of the page content. I’m guessing that I can have a delve around http://simile.mit.edu/wiki/Sifter and find out more..
I’m familiar with Exhibit and Potluck, partly because I went to a semantic web workshop run by Eric Miller and Brian Sletten a couple of months ago and they demo’d a few bits from Simile. Immensely cool.
I also got carried away looking at Timequilt http://www.vimeo.com/808290 – would love to have a crack at pointing this at our museum data set…any chance..? 🙂
Cheers
Mike
Hi Mike,
There’s a link to a conference paper on Sifter, but admittedly the automatic scraping isn’t good enough for general use. So Sifter remains only a research prototype. I’m more of an HCI guy than a machine learning guy, so I focused more on the interactions in Sifter than the actual screen scraping 🙂
Regarding Timequilt, I did that at Microsoft Research and they have the code … It’s from 2004, so a bit old. You might want to look at PicLens (https://addons.mozilla.org/en-US/firefox/addon/5579) or something newer.
Cheers,
David
It’s nice to see some ambitious ideas coming from humanities…
I tried Dapper last year and found it quite limiting in its functions…
I’ve bookmarked the mashedmuseum to keep an eye on the project.
Best of luck and keep up the good work!
Andy, cheers, and apologies for delay ok’ing your comment. I was on holiday 🙂
Are you sure SWTT had nothing to do with the genesis of this, Mike? No mention of it… ;^)
@mikelowndes – you only invited me to one of the workshops (the last one, I think), so no 🙂 (still bitter that I got crapped on by a man-size seagull that day…)